Nature of Code - Week 7
04 May 2017
courses, documentation, noc
My final project for Nature of Code was Wikipediae, an alternate version of Wikipedia generated by a recursive neural network (RNN) algorithm trained on a data dump of Wikipedia.
The goal of the project was to host a series of linked webpages that were aesthetically similar to Wikipedia, where the text is entirely generated. I was hoping the output would contain an entire alternate universe, with its own countries and geography, political systems, celebrities and cultural events, etc. That kinda happened.

I used Andrej Karpathy'schar-rnn library, and used NYU’s HPC environment for training and sampling. It took a while to get everything setup on HPC since it's its own computing environment with its own way of installing/loading software and for submitting jobs to the server.
The results were mixed. Here's what the actual Wikipedia dump looks like.

And here's an example of the output from char-rnn.
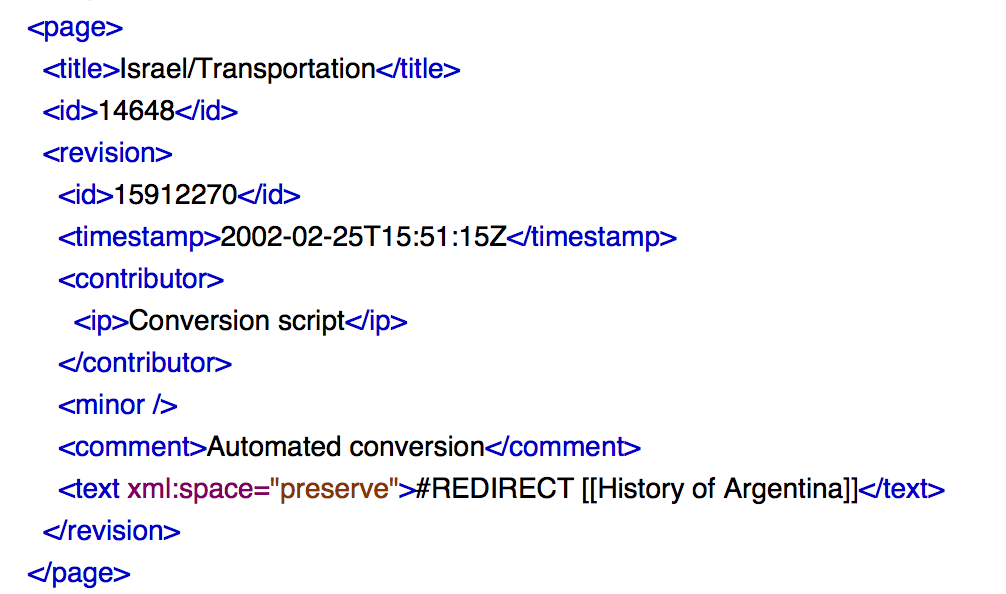
As you can see, it does an impressive job of picking up the markup structure. It doesn't, however, do a good job of creating convincing articles. The language is pretty close to being gramatically correct, but it doesn't quite make sense. For instance, it doesn't know that Alexander the Great is a person and should create a page with the typical sections for a biography (Early Life, Major Event 1, Major Event 2, Death).
One important parameter that I played with was Temperature. Karpathy notes, "Higher temperatures cause the model to take more chances and increase diversity of results, but at a cost of more mistakes." A temperature of around 0.5 worked best for this corpus. If the temperature was too low (i.e. 0.1), it would get stuck and just repeat phrases for a long time.

Too high and the output was too much nonsense.

For next steps I would like to play with the parameters more to get a more optimized training run. Additionally, I had to cut the corpus by quite a lot so the training iterations would take hours rather than days, so it would be good to have more time to run over the entire corpus or find a more scientific way to sample than just deleting massive chunks.
- Email: coblezc@gmail.com
Twitter: @coblezc - CC-BY