Programming A to Z - Week 3
26 Sep 2017
documentationcoursesa2z
I had an ambitious goal this week. I wanted to created a script that gets the article links on the front page of various news sites (left-leaning, right-leaning), grab the text of those articles, and then use named entity recognition to extract the names of places referenced in those articles. I am curious to how often various news agencies refernce places, which places, and how those lists compare.
I started with the New York Times as my test case. I used Beautiful Soup to extract the links from the front page. Here's a sample of the first 5 links

Then I used Selenium to take those article links and extract the headline and the story text. Here's an example - the first line is the headline and the subsequent lines are actual article.
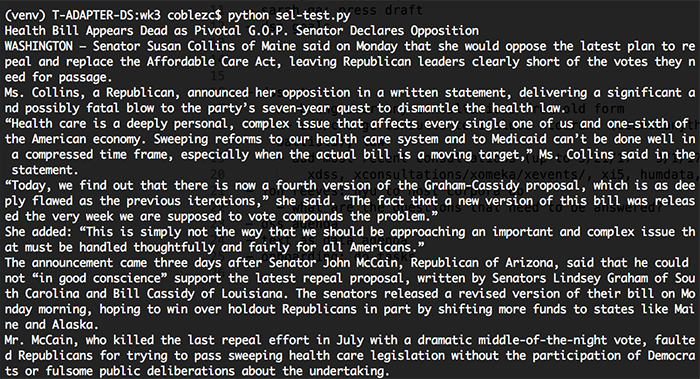
I'm curious about learning more about spaCy and wanted to use that to do named entity recognition (NER). It's possible to do with spaCy but there's a bit of a learning curve. Using the NER functions built into Stanford's NLTK might be a simpler way to go.
- Email: coblezc@gmail.com
Twitter: @coblezc - CC-BY