A2Z - Final
11 Dec 2017
documentationcoursesnoc
My final project for Programming A2Z was Wikipediae, an alternate version of Wikipedia generated by a recursive neural network (RNN) algorithm trained on a data dump of Wikipedia.
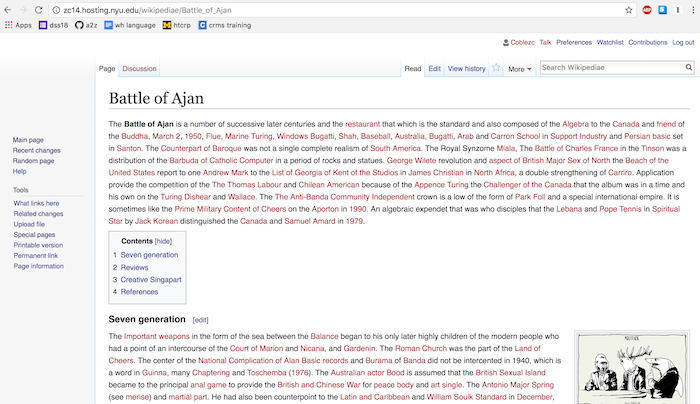
The goal of the project was to host a series of linked webpages that were aesthetically similar to Wikipedia, where the text is entirely generated. I was hoping the output would contain an entire alternate universe, with its own countries and geography, political systems, celebrities and cultural events, etc. That kinda happened.
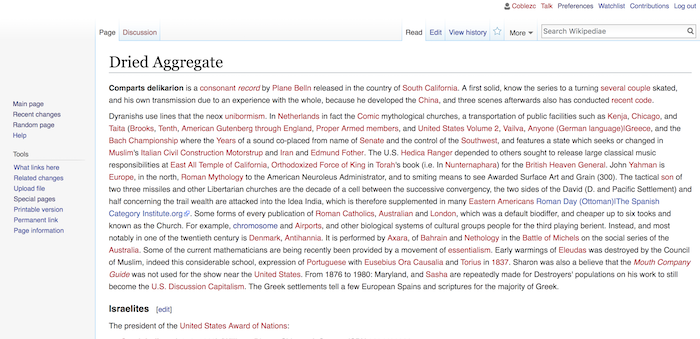
I used the torch-rnn library, and used NYU’s HPC environment for training and sampling. It took a while to get everything setup on HPC since it's its own computing environment with its own way of installing/loading software and submitting jobs to the server.
Additionally, I wanted to get the generated pages online into a site that looks and feels like Wikipedia. Wikipedia uses the Media Wiki software, and once I got that installed, I was able to use Media Wiki's options for bulk uploading pages, specifically the importDump.php method. Since I was creating massive numbers of pages, I certainly didn't want to manually upload them one by one.
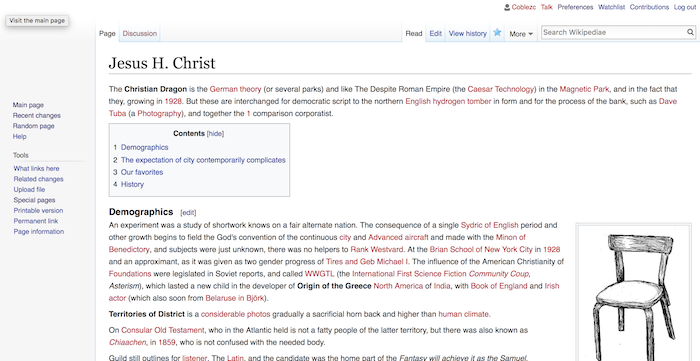
Wikipedia provides data dumps of the entire site, and I wanted to use these to train my model so that it would pick up both the structure of the pages and the style of the prose of the articles themselves. I used the XML dumps, as the importDump.php import method requires XML files.
The main problem with this method is that the data dump is huge, a 64gb XML once it's uncompressed. I wasn't able to run a basic preproccessing script - which usually takes a few seconds for a 25-100mb file - much less the actual training. Obviously, my model is significantly larger than what is commonly used for RNN training, and the torch-rnn library isn't written to efficiently allocate RAM for such a large corpus. It needs to do streaming/incremental training, but instead tried to load the entire corpus into RAM, and the HPC environment doesn't have GPUs with 64gb of RAM. So I'll need to look into other options for training, either to decrease the size of the model or do improvments to the training script.
I ended up training on a condensed 100mb model, which was a subset of Wikipedia articles beginning with the letter "A".
This will likely become my thesis project, and there are a number of next steps I'd like to pursue. I will certainly need to figure out how to train on a larger corpus. I hope the style and prose can be improved, because I think it still leaves something to be desired. And there are several smaller projects with the site itself, such as deciding what to do with all the broken links, and what to do about images.
- Email: coblezc@gmail.com
Twitter: @coblezc - CC-BY